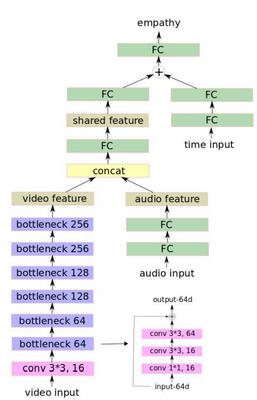
We propose a multi-modal method for the OneMinute Empathy Prediction competition. First, we use bottleneck residual and fully-connected network to encode facial images and speeches of the listener. Second, we propose to use the current time stage as a temporal feature and encoded it into the proposed multi-modal network. Third, we select a subset training data based on its performance of empathy prediction on the validation data. Experimental results on the testing set show that the proposed method outperforms the baseline methods significantly according to the CCC metric (0.14 vs 0.06).
Shi Yin
Technical Researcher
Can Wang
PhD
Shangfei Wang
Professor of Artificial Intelligence
My research interests include Pattern Recognition, Affective Computing, Probabilistic Graphical Models, Computation Intelligence.