Identity- and Pose-Robust Facial Expression Recognition through Adversarial Feature Learning
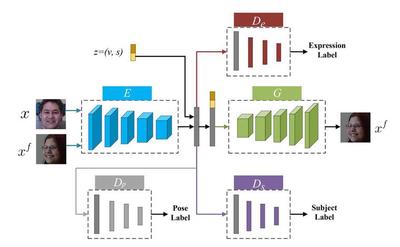
Existing facial expression recognition methods either focus on pose variations or identity bias, but not both simultaneously. This paper proposes an adversarial feature learning method to address both of these issues. Specifically, the proposed method consists of five components: an encoder, an expression classifier, a pose discriminator, a subject discriminator, and a generator. An encoder extracts feature representations, and an expression classifier tries to perform facial expression recognition using the extracted feature representations. The encoder and the expression classifier are trained collaboratively, so that the extracted feature representations are discriminative for expression recognition. A pose discriminator and a subject discriminator classify the pose and the subject from the extracted feature representations respectively. They are trained adversarially with the encoder. Thus, the extracted feature representations are robust to poses and subjects. A generator reconstructs facial images to further favor the feature representations. Experiments on five benchmark databases demonstrate the superiority of the proposed method to state-of-the-art work.
Can Wang
PhD
Shangfei Wang
Professor of Artificial Intelligence
My research interests include Pattern Recognition, Affective Computing, Probabilistic Graphical Models, Computation Intelligence.