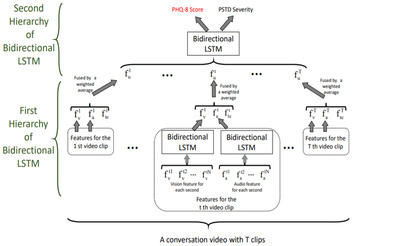
Depression has a severe effect on people’s life. The artificial therapy of depression is facing a shortage of expert therapists. The automatic detection of depression can be an auxiliary means of artificial therapy. As a delicate mental symptom, depression cannot be accurately distinguished via single modal observation. To address this, our work utilizes vision, audio and text features. For vision features, gaze direction, 3D position, the orientation of the head and 17 facial action units are considered. For audio, the hidden layers of pre-trained deep models are used. For text, we build features from two aspects. The first one is the semantic embedding of the whole sentence. The second one is the emotional distribution of several words with obvious emotional tendencies. A subject engaging in a multi-turns conversation may produce several video clips sharing a similar theme. Facing the hierarchical characteristic of such data, we design a framework consisting of two hierarchies of bidirectional long short term memories (LSTM) for the depression detection task. The first hierarchy of bidirectional LSTM extracts vision and audio features for every video clip. The second hierarchy of bidirectional LSTM fuses the visual, audio and textual features and regresses the degree of depression. The indicator in concern in the DDS challenge is the PHQ-8 Score, while the proposed method jointly learns the PTSD Severity to facilitate the prediction of the PHQ-8 Score under a multi-task learning schema.
We conduct training on the official training set and test it on the official testing set of the challenge. Compared to the optimal results in baseline methods, our method increases Concordance Correlation Coefficients (CCC) by 19.64% and decreases Root Mean Square Error (RMSE) by 1.79% on the development set, and also increases CCC by 268.33% and decreases RMSE by 13.66% on the testing set, which means a significant performance compared to the baseline methods.
Shi Yin
Technical Researcher
Shangfei Wang
Professor of Artificial Intelligence
My research interests include Pattern Recognition, Affective Computing, Probabilistic Graphical Models, Computation Intelligence.