Exploiting Self-Supervised and Semi-Supervised Learning for Facial Landmark Tracking with Unlabeled Data
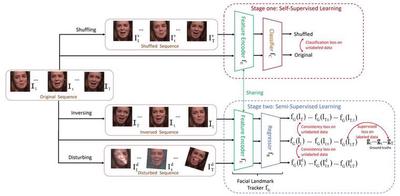
Current work of facial landmark tracking usually requires large amounts of fully annotated facial videos to train a landmark tracker. To relieve the burden of manual annotations, we propose a novel facial landmark tracking method that makes full use of unlabeled facial videos by exploiting both self-supervised and semi-supervised learning mechanisms. First, self-supervised learning is adopted for representation learning from unlabeled facial videos. Specifically, a facial video and its shuffled version are fed into a feature encoder and a classifier. The feature encoder is used to learn visual representations, and the classifier distinguishes the input videos as the original or the shuffled ones. The feature encoder and the classifier are trained jointly. Through self-supervised learning, the spatial and temporal patterns of a facial video are captured at representation level. After that, the facial landmark tracker, consisting of the pre-trained feature encoder and a regressor, is trained semi-supervisedly. The consistencies among the tracking results of the original, the inverse and the disturbed facial sequences are exploited as the constraints on the unlabeled facial videos, and the supervised loss is adopted for the labeled videos. Through semi-supervised end to-end training, the tracker captures sequential patterns inherent in facial videos despite small amount of manual annotations. Experiments on two benchmark datasets show that the proposed framework outperforms state-of-the art semi-supervised facial landmark tracking methods, and also achieves advanced performance compared to fully supervised facial landmark tracking methods.
Shi Yin
Technical Researcher
Shangfei Wang
Professor of Artificial Intelligence
My research interests include Pattern Recognition, Affective Computing, Probabilistic Graphical Models, Computation Intelligence.