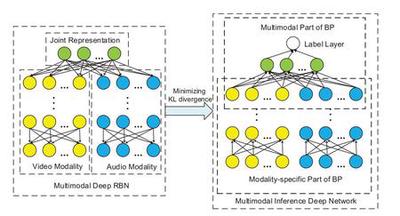
In this paper, we propose a new multimodal learning method, multimodal deep regression Bayesian network (MMDRBN), to construct the high-level joint representation of visual and audio modalities for emotion tagging. Then the MMDRBN is transformed into an inference network by minimizing the KL-divergence. After that, the inference network is used to predict discrete or continuous affective scores from video content.